
As data continues to grow in volume and diversity, it’s important to have efficient and flexible ways to store and analyze it. Apache Parquet is a columnar storage format designed for big data processing frameworks like Apache Hadoop and Apache Spark.
Apache Parquet is an open source file format that stores data in columnar format. As a columnar data storage format, it offers several advantages over row-based formats for analytical workloads. Your choice of data format can have significant implications for query performance and cost.Let’s Understand how apache Parquet work its use cases, what are some benefits and drawbacks of it.
How Apache Parquet Works
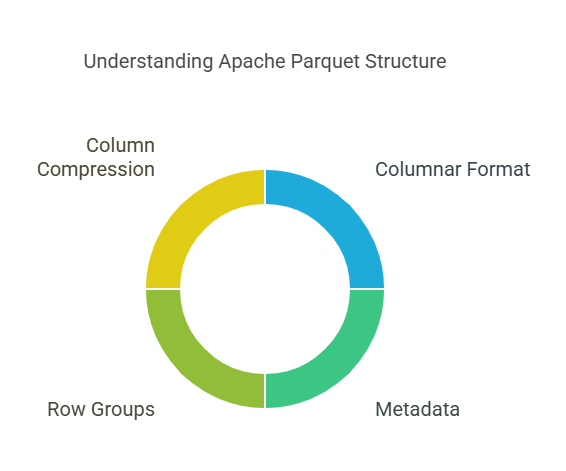
Parquet is designed to be efficient for both read and write operations. It stores data in a columnar format, but also includes metadata that describes the structure of the data. This metadata includes information like the schema, data types, and compression algorithms used for each column.
Parquet files are divided into row groups, which are further divided into columns. Each column is compressed individually, and can use a different compression algorithm. This allows for optimal compression and query performance for each column.
Use Cases for Apache Parquet
Parquet’s columnar storage format makes it an ideal choice for big data processing frameworks like Apache Hadoop and Apache Spark. It can handle large datasets and complex queries with ease, while also providing flexible schema evolution and efficient compression.
Parquet is also commonly used for data warehousing, where it provides fast query performance and efficient storage for large datasets. It’s also a popular choice for machine learning applications, where it can handle large amounts of training data and provide fast access to specific columns.
Benefits of Parquet Big Data
- Good for storing big data of any kind (structured data tables, images, videos, documents).
- Saves on cloud storage space by using highly efficient column-wise compression, and flexible encoding schemes for columns with different data types.
- Increased data throughput and performance using techniques like data skipping, whereby queries that fetch specific column values need not read the entire row of data.
- Apache Parquet is implemented using the record-shredding and assembly algorithm, which accommodates the complex data structures that can be used to store the data.
- Parquet is optimised to work with complex data in bulk and features different ways for efficient data compression and encoding types. This approach is best especially for those queries that need to read certain columns from a large table. Parquet can only read the needed columns therefore greatly minimising the IO.
Drawbacks of Apache Parquet
- Parquet is a binary-based (rather than text-based) file format optimised for computers, so Parquet files aren’t directly readable by humans. You can’t open a Parquet file in a text editor the way you might with a CSV file and see what it contains. There are utilities that convert the binary representation to a text-based one, such asparquet-tools, but it’s an extra step.
- Parquet files can be slower to write than row-based file formats, primarily because they contain metadata about the file contents. For analytical purposes, these slower write times are more than made up for by fast read times. However, for situations where data freshness and event latency are most important (e.g., in the 10s of milliseconds range), it can be worth leveraging a row-based format without statistics like Avro or CSV.
Apache Parquet vs. CSV
CSV is a simple and common format that is used by many tools such as Excel, Google Sheets, and numerous others.While CSV files are easily opened for human review and some data analysts are comfortable working with large CSV files, there are many advantages to using Apache Parquet over CSV.
Parquet is better suited for OLAP (analytical processing) workloads than CSV. CSV is good for interchange because it’s text-based and a very simple standard that’s been around for a very long time, but Parquet’s columnar structure and statistics enable queries to zero in on the most relevant data for analytic queries by selecting a subset of columns and rows to read.
Conclusion
Apache Parquet is a versatile and efficient columnar storage format that’s well-suited for big data processing and analytics. Its ability to handle large datasets, provide efficient query performance, and support flexible schema evolution make it a popular choice for a wide range of use cases. If you’re working with big data, it’s worth taking a closer look at what Apache Parquet has to offer.
FAQs
What is Apache Parquet?
Apache Parquet is a columnar storage format that allows data to be stored efficiently in a compressed and optimized way. It is designed to be highly scalable, compatible with a variety of data processing frameworks, and can be used for both batch and real-time processing.
What are the advantages of using Apache Parquet?
Apache Parquet offers several advantages over other storage formats. It is highly efficient, providing fast read and write times, and supports a wide range of data types. Additionally, it can be used with a variety of data processing frameworks, including Hadoop, Spark, and Hive, and can be easily integrated into existing data pipelines.
How does Apache Parquet compress data?
Apache Parquet uses a combination of compression techniques, including dictionary encoding, run-length encoding, and bit-packing. This allows data to be stored in a highly compressed format, reducing storage requirements and improving read and write times.
What data types does Apache Parquet support?
Apache Parquet supports a wide range of data types, including numeric types, boolean, binary, and string data. It also supports more complex data types, such as arrays, maps, and structs.
How does Apache Parquet handle schema evolution?
Apache Parquet supports schema evolution, which allows for changes to the schema over time without requiring a full data reload. New columns can be added to the schema, and existing columns can be renamed or deleted. This makes it easy to handle changes to the data over time, without requiring significant changes to the data processing pipeline.


